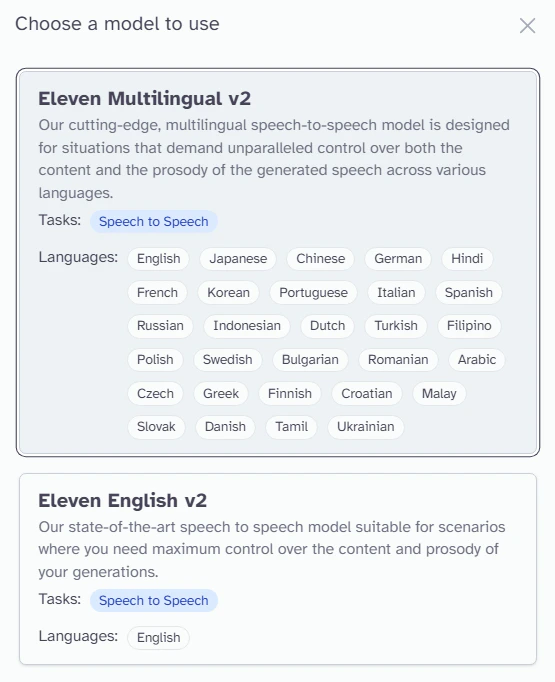
- Greater accuracy with whispering
- The ability to create audible sighs, laughs, or cries
- Greatly improved detection of tone and emotion
- Accurately follows the input speaking cadence
- Language/accent retention
Record or Upload
Audio can be uploaded either directly with an audio file, or spoken live through a microphone. The audio file must be less than 50mb in size, and either the audio file or your live recording cannot exceed 5 minutes in length. This is consistent among all Subscription tiers, and is to ensure a stable output. If you have material longer than 5 minutes, we recommend breaking it up into smaller sections and generating them separately. Additionally, if your file size is too large, you may need to compress/convert it to an mp3.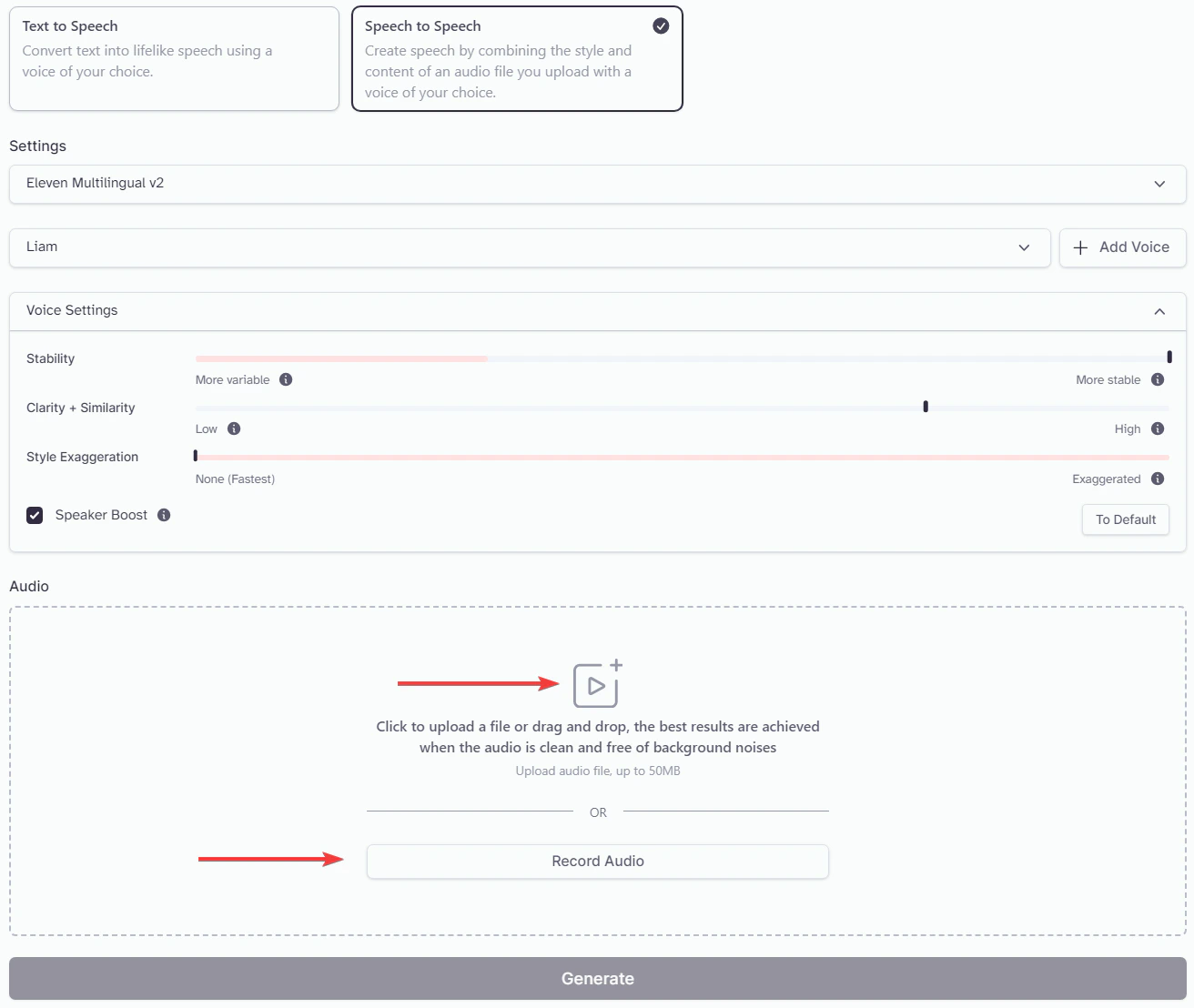
Models
STS is now available for all 29 languages currently offered in Text-to-Speech (TTS) through the release of our new M2 model. The English v2 model is also available for specifically English speech.